
May 08, 2017 / by Torsten Bøgh Köster / CTO / @tboeghk
Taming PostgreSQL autovacuum
We’re at shopping24 are big fans of PostgreSQL as it leverages the latest SQL specifications in conjunction with great operability, a large open source community and last but not least incredible query performance - as long as Autovacuum is tamed. Before continuing, read the Postgres Autovacuum is Not the Enemy post by Joe Nelson.
The PostgreSQL setup at shopping24
We have hordes of PostgreSQL servers for our backend, warehousing and frontend services. Most are running on bare metal with about 40 cores, 256G RAM and lots of SSDs with data and indexes spread among disks in RAID10 arrays. When it comes to Autovacuum, there is no “one size fits all”. When tuning Autovacuum, we usally start with the default settings and check table bloat regularly.
Tuning vacuum & autovacuum
When it comes to tuning your autovacuum, you should monitor your table bloat query time on problematic tables. For us, pghero.sql was a great starting point.
Our by far hardest tuning candidate was our online assortment database. Every product delivered via our api or portal is read from this PostgreSQL database. With our roughly 100M products, the de-normalized database is pretty decent sized (400G).
We have about 20M daily updates on our product database. Updates and queries run in parallel on the cluster. Query load is quite high and spread across two replication slaves. Updates are handled by a single master node. After a couple of weeks in production, we saw a huge increase in table bloat, maxing at above 100%! Along that, query times and storage costs increased. But most problematic: For us, it felt that autovacuum would either kick in during big important product updates or during prime time. Both was problematic either in terms of product update throughput or product query time - in the end: it was problematic for our money.
1) The manual VACUUM (offline)
To get the database back up to speed, we stopped updating, stopped replication and split the cluster. On the master node, we performed a tedious FULL VACUUM ANALYZE on the database that took hours to finish. Then, we wiped one slave node after another and did a full replication. The overall process took about 12h to complete and left us with a (almost) zero bloat database. We still do this on a yearly basis, but the process takes way too long and is way too error prune.
2) The crontabbed VACUUM
To make long things short: What a bad idea! The FULL VACUUM above left us with a incredible fast and responsive database. So we thought, it might be a good idea, to disable all autovacuuming and schedule nightly FULL VACUUM during low traffic. In a cluster setup, all Vacuum & Autovacuum operations are issued on the master and vacuumed data is replicated to the slaves. I recognized that it wasn’t the best idea as PagerDuty alarmed us, that parts of our infrastructure was down - exactly during that vacuum. The FULL VACUUM operation locks a table and postpones all read operations. That lead to failure in our frontend apis …
3) Dynamic autovacuum
In fact, what we wanted was a intense autovacuum during night time and emergency autovacuum only during peak hours. Our product tables are partitioned into 10 tables. Each has a size of rougly 10GB each and 10M rows. On each table, we have ~ 2.5M updated rows daily. Half of those updates are hot updates that do not lead to dead rows in the database. On those tables, a autovacuum_vacuum_scale_factor of 0.4 would trigger an autovacuum as soon as 1M rows are updated. An autovacuum_vacuum_scale_factor of 0.0.5 would trigger an autovacuum as soon as 125K rows are updated. PostgreSQL computes the vacuum threshold as follows:
vacuum threshold = vacuum base threshold + vacuum scale factor * number of tuples
As you can see, with that many rows, the base threshold does not have any effect on the computed vacuum threshold. In order to efficiently vacuum the tables in memory (max 10 workers in parallel), we configured PostgreSQL a huge maintenance_work_mem of 92GB and a cronjob after and before prime time to change the autovacuum_vacuum_scale_factor only:
# run at prime time end (late evening)
psql -c 'ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.05;' \
database-name && psql -c 'SELECT pg_reload_conf();' database-name"
# run before prime time (early morning)
psql -c 'ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.4;' \
database-name && psql -c 'SELECT pg_reload_conf();' database-name"
This magic trick is in production for a couple of months now and leads to database tables that gather bloat during prime time but have a better query performance and dramatically reduce bloat during night time but are still responsive. The graphs below shows table bloat percentage during a 24 hour and 7 days time frame:
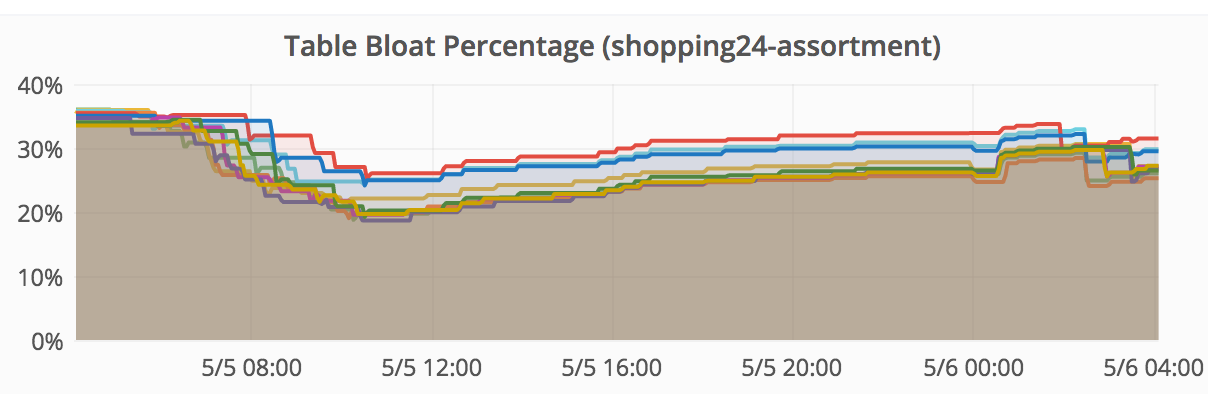
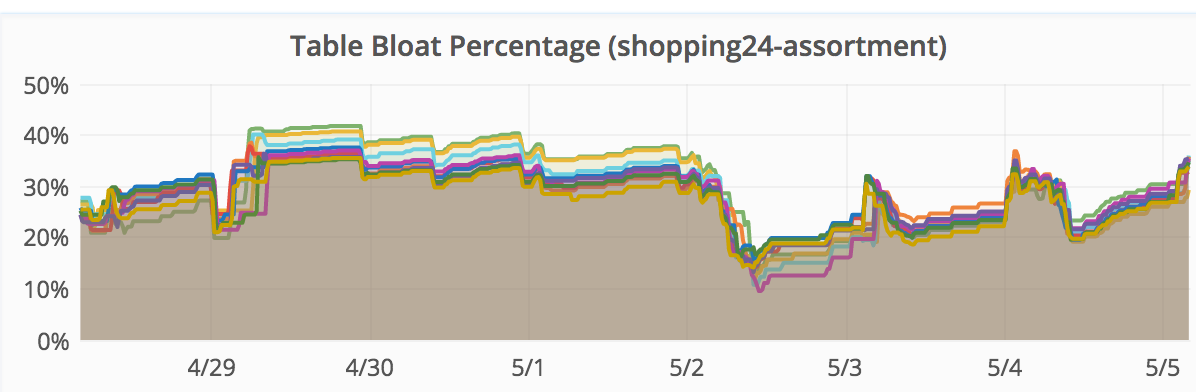
When setting the execution times for the cronjobs above, remember that autovacuums do not stop when you’re increasing the scale factor. The new scale factor will be considered for the next free autovacuum worker.
Next steps
We’re eager to test PotgreSQL 10 and the new logical replication feature. This might be a game changer in replication and data flow. If you want to play around with our large amount of data: We’re looking for Data Engineers!