February 15, 2016 / by Tobias Kässmann / Software engineer / @kaessmannt
Solr and RAKE: Your Keywordextraction toolkit
Keywordextraction is a nice Natural language processing (NLP) technology to reduce long text to it’s relevant tags. There are a lot of use cases in the Text-Mining field: From reduce your lucene index size, speedup your search requests up to deliver relevant advertisements to your customers based on text. Let me give you a hint how we deal with this problem.
Keywordextraction is hard
We’ve tried a lot of stuff from OpenNLP to Apache Stanbol, but Stanbol is far from being a reliable product and includes a huge technology overhead. The OpenNLP implementation in Solr is also too slow for our usecases, so we decided to dig deeper into the matter. First we started to pick what algorithms are in use and which will be the best to fit our requirements. To do this in a very basic way, we found on google code a great toolkit for some basic algorithm comparisons. Here we are with a bunch of nearly undocumented and personalized code: Jate. But we gave it a chance and after a while we were not disappointed. Finally we figured out a comparison test with all keywordextraction algorithms we wanted to test. Just a short list which algorithms are compared:
- Average Corpus Term Frequency
- Chi-square
- C-Value
- Frequency
- Justeson & Katz
- NC-Value
- RAKE
- RIDF
- Tf-Idf
Evaluation
The tests return a text file for each algorithm containing the extracted keyword and a score. You have to keep in mind that some algorithms are based on statistic calculations, so the quality of them depends on how large the input is. This is the reason why you have to use heterogeneous texts for your test cases like:
- Long vs. short texts
- Simple words vs. crazy punctuations (like camera descriptions)
- Lot’s of stopwords vs. few stopwords
Finally we took a look at the results and identified a algorithm that provided us the most fitting results.
The RAKE Algorithm extracts the most usefull words for our use cases. We thought that it was possible to produce some better results by modifying the algorithm a bit. Based on the extracted keywords, we filtered just the keyword size (keywords with less than 3 tokens) that we wanted. Unlike just a 1/3 sublist which is recommended in the paper.
Solr integration
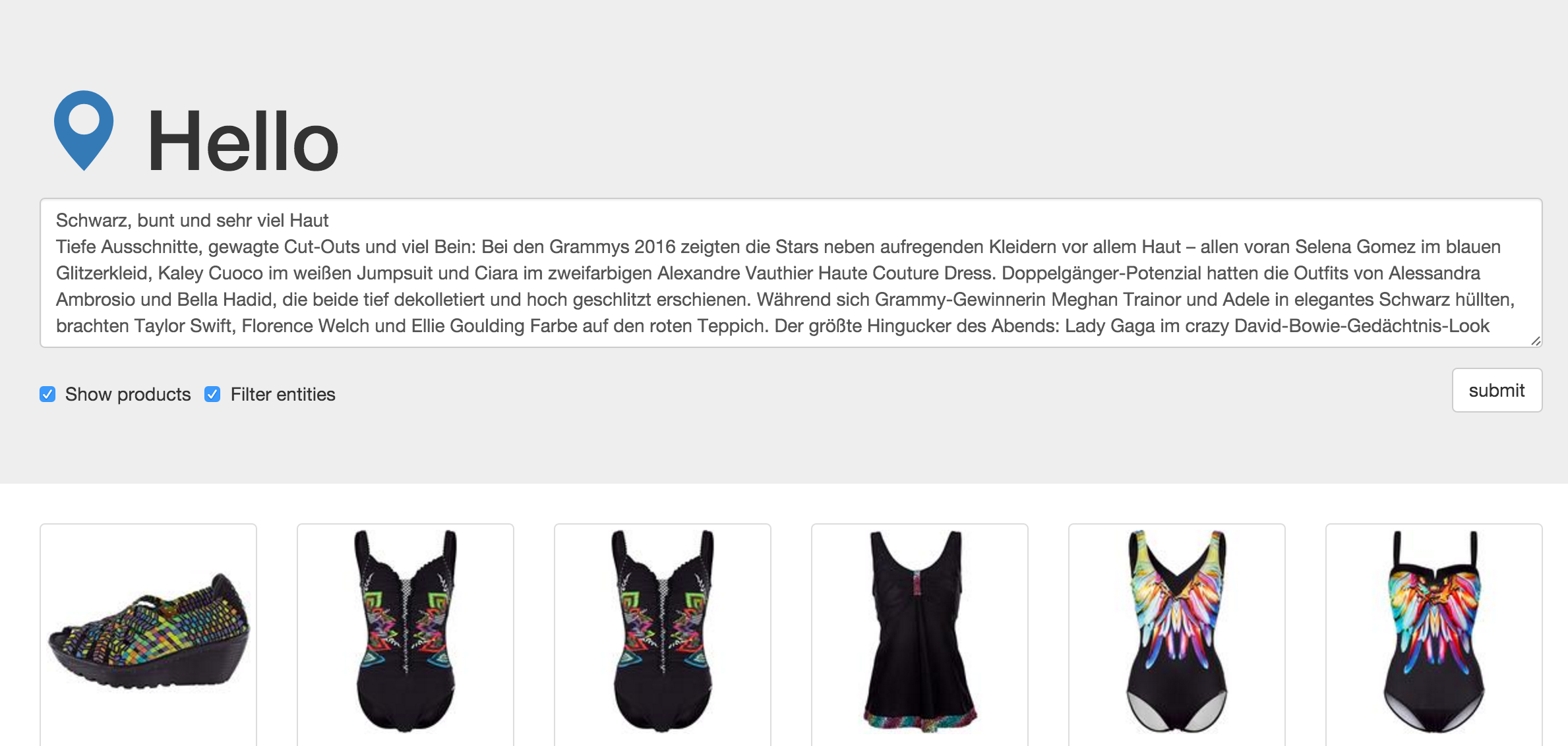
We implemented this solution directly in Solr by integrate a KeywordextractionRequestHandler. This gaves us the advantage to directly combine this functionallity with much more options like further postprocessing steps.

It’s configureable and usefull to filter the tags by a entity recognition to know which terms you’ve got in your data and are possible to search for. To give the management and users direct feedback how good this term extraction works, we passed the extracted and filtered keywords to a intern search request and displayed the returned products. At the end it was possible to submit a text and get related products for this. We also provide a simple frontend for better usability.