October 09, 2013 / by Dennis Kallerhoff / Team lead operations / @wuseldusel83
Crowdsourcing + prediction engine = better product information at low costs
This blog posts explains how to use a combination of crowdsourcing and prediction to improve your product information.
Why product information matters
Here is our challenge: (a) we have a lot (!) of products that change often, (b) we need good product data and (c) we don’t want humans to do the tagging of our products. How to automatically improve your product data?
Let’s start at the beginning. If I talk about product data I’m talking about structured data that helps describing a product more precisely: the color of a shirt, the material of a dress or the heel of a shoe. Our basis product information (price, title, description) we get from our shop partner. But that is (often) not good enough. We need more information about every single product so that (a) our search is precise and (b) we can offer filters so that users can drill down into categories and search results.
Prediction + Crowdsourcing in action
Down to work: Today I’m going to talk about the combination of crowdsourcing and prediction engines:
- As for crowdsourcing we pay user in the cloud to do simple, small tasks like classifying products.
- As for prediction engines there are classifiers that can be trained with small subsets of information to detect pattern in lager sets of information. A common example for prediction is spam detection. Take 1.000 emails and tag each email if it is spam or not. Based on this information a prediction engine tries to detect pattern how to find spam. With this pattern (called model) in place you take a larger set of 100.000 emails and the engine will tell you what mails are spam (in percent).
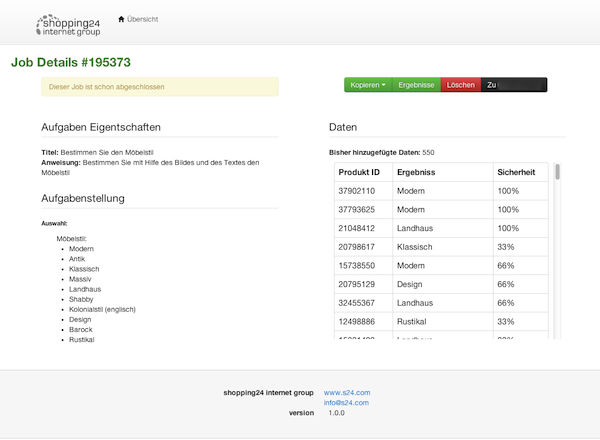
Now let’s put these two amazing technologies together in an ecommerce context. As you can imagine it is hard work to classify 1.000 emails in the example above. And detecting spam is an easy task compared to classifying the heels of a shoe (at least for an IT guy). So instead of spending hours and hours for classifying product attributes we give that task to the cloud.
The cloud itself even mostly does QA. If you give each task to three different people and three people say this is a wedge (for IT guys: this is a kind of heel), then it is a wedge. The qualified and classified data is given as training set to a prediction engine (e.g. Google Prediction Engine). Based on training set the engine calculates a model on how to detect heels. After testing the model and being ok with the resulting product information we include the prediction model in our workflow. Every new product in that shoe category is send to the prediction engine and we have our valuable product information.